Since 1994, the TINKER project at NC State, and since 2008, at Georgia Tech, has removed traditional of layers of abstraction to uncover new techniques for high performance microprocessors. The project has focused on breaking down the layers between the microarchitecture, the instruction set, the compiler and the operating system.
Since the slowdown in processor frequency in 2005, and its related slowdown in single thread performance, TINKER has worked on levels 2 through 4 of the IEEE Rebooting Computing disruption diagram:
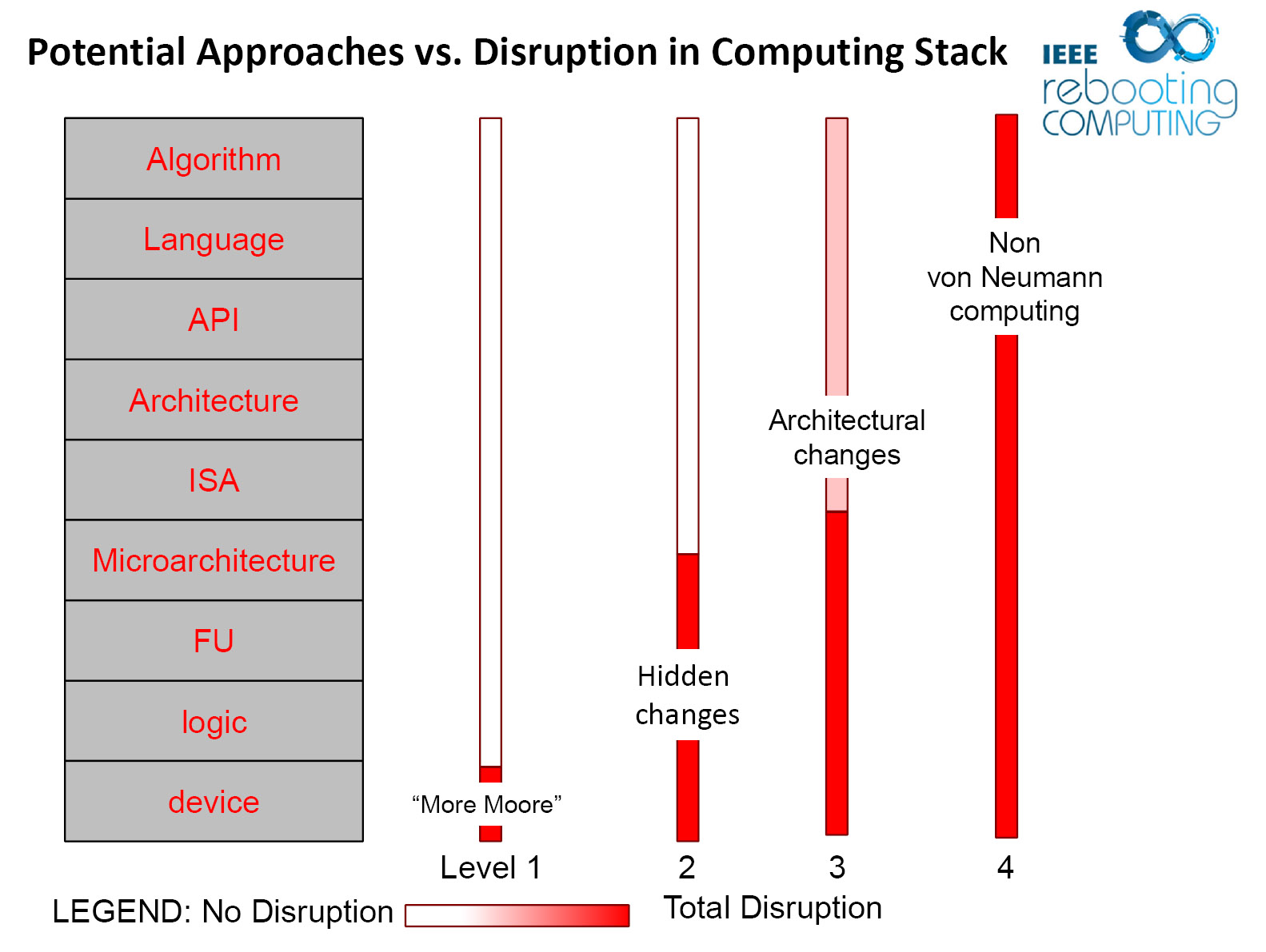
This work is based on Tom Conte's co-founding of the IEEE RC initiative. Since 2016, TINKER is part of CRNCH, an interdisciplinary research center at Georgia Tech with a mission to reboot computing.